AI issue prioritization is defined as the automated process of scoring and ranking software bugs, vulnerabilities, and technical debt by their measurable effect on code health, user experience, and system stability. Understanding how AI prioritizes issues by code impact is now a core competency for development teams, given that 84% of developers currently use or plan to use AI tools in their workflows. Frameworks like TriageIQ and ECOA AI have moved this process from gut-feel sprint planning to data-driven triage that takes seconds, not days.
How AI prioritizes issues by code impact: the core methodology
AI issue prioritization works by assigning a numeric score to each issue based on weighted factors tied directly to code behavior and business risk. The most widely referenced model is the ECOA AI scoring formula: Priority Score = (Impact × 0.5) + (Effort × 0.3) + (Alignment × 0.2). Any issue scoring above 8 is automatically labeled Critical. That single formula cuts triage time by 70% while surfacing high-impact, low-effort issues first.
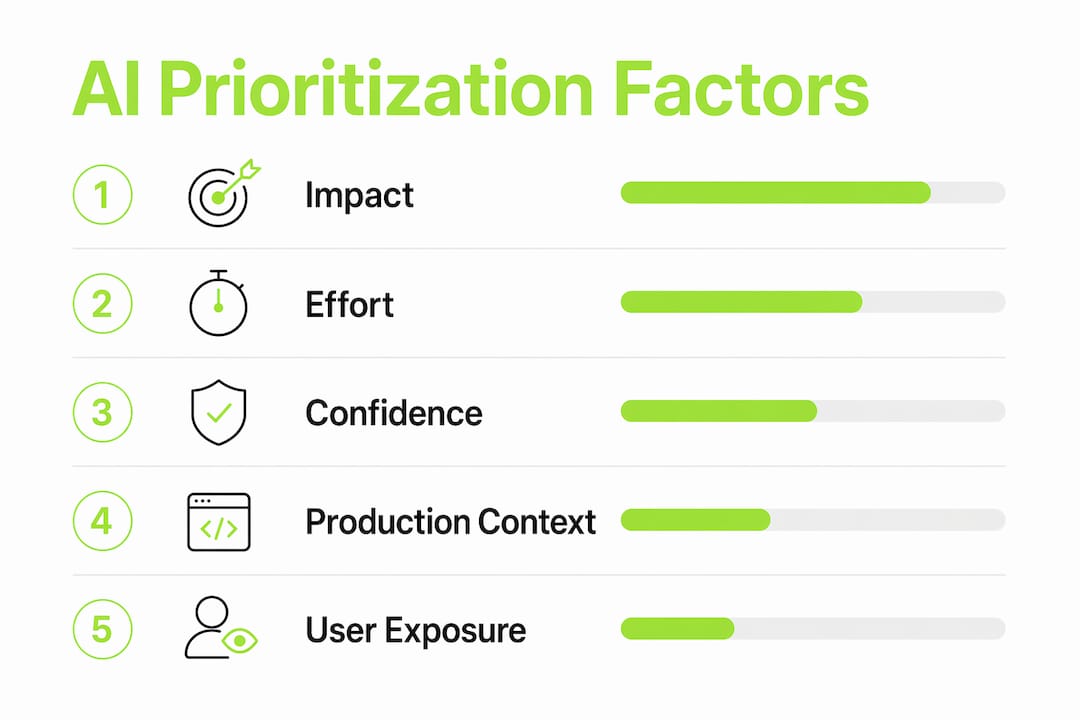
The three factors in the ECOA model each carry a specific meaning in code terms. Impact measures the blast radius of a bug: how many users are affected, which services break, and whether data integrity is at risk. Effort scores the estimated engineering cost to fix the issue. Alignment checks whether resolving the issue supports current product or business goals.

AI models translate these scores into priority labels that feed directly into sprint backlogs or ticketing systems like Jira or Linear. A score above 8 triggers a Critical label and immediate escalation. Scores in the 5–8 range become High priority items queued for the next sprint. Anything below 5 is logged but deprioritized until bandwidth allows.
The data inputs that feed these scores include code complexity metrics, affected user counts from session data, error frequency from production logs, and engineering work estimates. AI models prioritize issues that threaten correctness, security, and data integrity above all other categories. This focus reduces cognitive load by surfacing the few most critical issues rather than flooding engineers with hundreds of low-severity warnings.
Pro Tip: Build a scoring rubric specific to your product before deploying any AI triage tool. Define what "high impact" means in your codebase, whether that is payment flow failures, authentication errors, or data loss scenarios. AI models perform better when given explicit definitions rather than generic defaults.
| Factor | Weight | What it measures |
|---|---|---|
| Impact | 50% | User exposure, failure radius, data risk |
| Effort | 30% | Engineering hours to resolve |
| Alignment | 20% | Fit with current product priorities |
| Score above 8 | Critical | Immediate escalation required |
| Score 5–8 | High | Next sprint queue |
Does production context change how AI assesses code?
Static code analysis alone is not enough for accurate prioritization. Prioritization based solely on code diffs misses the actual blast radius of an issue in production. A function that looks clean in a diff can be causing thousands of errors per hour in a live environment.
Context-aware AI solves this by combining static analysis output with real production telemetry. Tools like Sentry provide error rates and stack traces. Datadog supplies latency metrics and service health data. When AI ingests both signals together, it can differentiate critical bugs from low-impact ones with far greater accuracy than any single data source allows.
The practical result is a prioritization model that blends three dimensions:
- Impact: How many users or services does this issue affect right now?
- Confidence: How certain is the static analysis that this is a real defect, not a false positive?
- Urgency: Does this need to be fixed before the next merge, or can it wait?
Clustering issues by these three dimensions prevents alert fatigue. Without clustering, a team might receive 200 flagged issues after a single deployment. With context-aware ranking, that list collapses to the 10 or 15 issues that actually require human attention. Severity ranking is the critical deliverable of any AI code review system. Without production context, the ranking loses its effectiveness.
Pro Tip: Connect your AI triage tool to both your error monitoring platform and your deployment pipeline. Issues flagged within 30 minutes of a deployment carry higher urgency weight than issues discovered during routine scans. Timing context is a signal most teams ignore.
Which AI prioritization frameworks and tools are worth comparing?
Three approaches dominate AI issue prioritization in 2026: rule-based triage systems, hybrid LLM plus static analysis models, and fully context-aware AI platforms.
TriageIQ, trained on 20,000 real issues, processes and prioritizes new issues at a median speed of approximately 3 seconds. It delivers structured output including priority label, expected resolution timeline, and suggested assignee. That speed makes it practical for teams running continuous integration pipelines where issues surface on every commit.
The ECOA AI framework takes a more transparent approach. Its weighted scoring model is open source, meaning teams can inspect and adjust the formula. That transparency builds trust with product managers who need to explain prioritization decisions to stakeholders.
Hybrid LLM plus static analysis tools, such as those built on the CodeGuru architecture, combine the pattern recognition of large language models with the deterministic output of static analyzers. The LLM interprets intent and context. The static analyzer confirms whether the code actually violates a rule. Together, they reduce false positives significantly.
| Framework | Speed | Transparency | Production context | Best for |
|---|---|---|---|---|
| TriageIQ | ~3 seconds | Moderate | Limited | High-volume CI pipelines |
| ECOA AI | Batch | High | Limited | Teams needing auditable scoring |
| Hybrid LLM + static | Variable | Low | Strong | Complex codebases with runtime risk |
The main trade-off across all three is transparency versus accuracy. Rule-based systems are easy to audit but miss nuanced context. LLM-based systems catch subtle issues but can be difficult to explain to non-technical stakeholders. AI models can show bias toward high-priority labels, which means every framework requires human review of edge cases, particularly issues with known workarounds that do not actually block users.
What are the best practices for teams using AI issue prioritization?
Effective AI prioritization does not happen by installing a tool and walking away. The teams that get the most value follow a structured implementation process.
Write explicit priority guidelines before deployment. Define Critical, High, Medium, and Low in terms specific to your product. A payment failure is Critical. A tooltip misalignment is Low. AI models perform better when given these definitions as system-level rules rather than learning them from scratch.
Build agent context over time. Successful teams build agent context over weeks, feeding the AI steering files, architectural documentation, and historical issue resolutions. This context lets the AI understand which parts of the codebase carry the highest risk before it acts autonomously.
Run a human-in-the-loop review for the first 60 days. Have a senior engineer or product manager review every Critical and High label the AI assigns. Track disagreements. Use those disagreements to fine-tune the scoring model or add new priority rules.
Integrate AI triage into backlog refinement. AI-generated priority scores work best when they feed directly into your backlog management process rather than sitting in a separate tool. Teams that keep AI triage separate from sprint planning end up ignoring it within two months.
Validate model outputs quarterly. AI models drift as codebases evolve. A model trained on your codebase from six months ago may misclassify issues in a newly added microservice. Schedule quarterly reviews of scoring accuracy against actual incident data.
Pro Tip: Create a "disagreement log" where engineers record every time they override an AI priority label. After 30 days, review the log as a team. Patterns in the disagreements reveal gaps in your priority guidelines or missing context in your AI configuration.
The role of developers is shifting from writing every line of code to planning, directing, and validating AI agents. Product managers who understand AI prioritization logic can contribute directly to that steering process, making cross-functional collaboration on triage a real competitive advantage.
Key Takeaways
AI issue prioritization works best when weighted scoring models are combined with production telemetry and explicit human-defined priority guidelines, not when any single signal drives the ranking alone.
| Point | Details |
|---|---|
| Weighted scoring drives triage | The ECOA AI model weights Impact at 50%, Effort at 30%, and Alignment at 20% for objective ranking. |
| Production context is non-negotiable | Combining Sentry error rates and Datadog latency data with static analysis prevents critical bugs from being buried. |
| AI speed enables CI-scale triage | TriageIQ processes issues in approximately 3 seconds, making real-time prioritization practical for every commit. |
| Human oversight corrects model bias | AI models favor high-priority labels; explicit rules and human review are required to catch edge cases. |
| Agent context improves over time | Teams that feed AI steering files and architectural knowledge see accuracy improve significantly over weeks. |
The uncomfortable truth about AI triage I keep seeing teams miss
Most teams adopt an AI prioritization tool expecting it to replace judgment. It does not. What it replaces is the tedious, error-prone work of manually sorting through 300 issues after a release. The judgment part, deciding what actually matters for your users and your business, still belongs to humans.
I have watched teams deploy TriageIQ or a similar tool, see the Critical queue fill up with 40 issues on day one, and immediately lose confidence in the system. The problem is almost never the AI. It is that the team never defined what Critical means in their context. The AI defaults to a generic definition, flags everything that looks risky by general standards, and the team drowns in false urgency.
The teams that get this right treat the AI as a first-pass analyst, not a final decision-maker. They spend two weeks writing priority guidelines before they turn the tool on. They assign one person to review the AI output daily for the first month. They treat every disagreement as a training signal. After 60 days, the AI starts to reflect their actual risk tolerance, and the queue becomes genuinely useful.
The skill shift this requires is real. Developers and product managers need to think more like data curators and less like reactive firefighters. Feeding an AI agent good context, reviewing its outputs critically, and updating its rules regularly is now part of the job. That is not a burden. It is the work that makes everything else faster.
— Dizzy
How Coevy fits into your AI triage workflow
Teams that want AI-assisted issue prioritization need more than a scoring formula. They need the contextual data that makes scoring accurate: session replays, reproduction steps, and user feedback attached directly to each issue.
Coevy captures that context at the moment an issue occurs. Its embedded widget attaches session data, auto-tags issues, and generates AI-powered reproduction steps before a ticket ever reaches your backlog. The result is that your AI triage model receives richer inputs, which means more accurate priority scores from the start. Coevy's upcoming codebase-aware AI agent reads your actual source code, not generic documentation, to deliver prioritization assistance tied to your real application logic. Teams looking to reduce triage overhead can see how Coevy works and start capturing friction where it happens.
FAQ
What is AI issue prioritization in software development?
AI issue prioritization is the automated scoring and ranking of software bugs and technical debt based on code impact, user exposure, and business risk. Frameworks like ECOA AI use weighted formulas to assign numeric priority scores that feed directly into sprint backlogs.
How does AI measure the impact of code issues?
AI measures code impact by combining static analysis output, production telemetry from tools like Sentry and Datadog, affected user counts, and code complexity metrics. The blended model weighs impact, confidence, and urgency together to produce a single priority score.
How fast can AI triage a software issue?
TriageIQ processes issues at a median speed of approximately 3 seconds, delivering a structured output that includes priority label and expected resolution timeline. That speed makes real-time triage practical for continuous integration pipelines.
Why do AI prioritization models sometimes get it wrong?
AI models tend to bias toward high-priority labels, which causes over-escalation of low-risk issues. Teams correct this by writing explicit priority guidelines and running human-in-the-loop reviews, especially for issues that have known workarounds.
How should product managers use AI prioritization data?
Product managers should use AI priority scores as a structured input to backlog refinement, not as a final decision. Reviewing AI-generated bug prioritization insights alongside user feedback and business goals produces the most accurate sprint planning outcomes.